
Supply Chain Data Analytics: Moving Beyond the Hype
The use of big data to create business insights that drive more customer-centric, demand-driven supply chains was one of the key strategic trends identified by Gartner Inc. analyst Stan Aronow in the firm’s 2014 Supply Chain Top 25 report. Yet, a separate Gartner survey found that while interest in big data technologies and services is at an all-time high, only 13 percent of respondents had actually deployed a big data solution.
What’s holding these organizations back? Among the most commonly cited barriers to adoption are: the large investment, security and privacy issues and a lack of business case. While these are valid and logical explanations, an equally plausible reason is the continued lack of clarity around exactly what big data is—and isn’t.
A Defining Moment
For example, even IT thought leaders cannot come to a consensus on the number of “Vs” it takes for data to be indisputably “big.” Gartner pegs the magic number at three: high volume, high velocity, and/or high variety. This description is one “V” short, according to IBM, which includes veracity in its big data characterization, while others still believe value, viability and visualization are necessary ingredients. So, how many “Vs” does it take? To quote Tootsie Pop’s esteemed Mr. Owl: “The world may never know.”
Why does it matter? Because the difference between big data and standard transactional data is not just a matter of semantics. Big data isn’t just “more” of the quantitative ERP- and CRM-type data companies have been utilizing for years to improve forecasts and efficiency. Big data includes these transactional database inputs, as well as qualitative/analytical records from a variety of non-traditional sources, including images, audio files, HTML, emails and social media. While the techniques to analyze both these data types are based on the same disciplines – probability theory, mathematical statistics, computer science and virtualization—big data can enhance predictive analytics because it is based on near real-time information, rather than historical patterns. In addition, since standard relational database tools typically do not have the speed, scalability or processing power required to handle large, complex data sets, understanding these distinctions is critical to determining which analytic tools, models and algorithms will be most effective in leveraging your data analytics’ capability to its fullest.
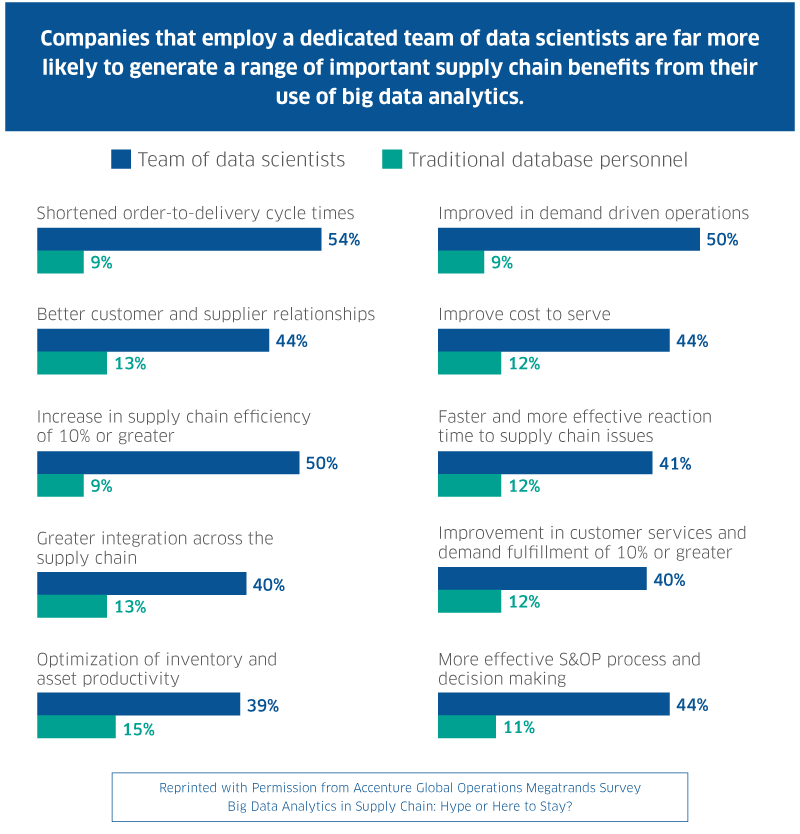 Less Talk, More Action
Less Talk, More Action
2015 is expected to be a transitional year for big data analytics. In a recent CIO magazine article, Gartner analyst Ian Bertram predicted big data is going to hit hype-cycle rock bottom—a state he ominously refers to as the “trough of disillusionment.” While this sounds like a pretty bleak outlook, the upshot is that after several years of astronomical projections and largely anemic results, enterprises will finally start to see the big data opportunity for what it is—and isn’t. They will realize that data hoarding is not a strategy; and they will accept that not all big data is useful, and not all useful data is big. This is where the road diverges for those who successfully capture and utilize supply chain data analytics and those who are derailed by information overload.
 Follow the Leaders
Follow the Leaders
Worried about being late to the party? With the relative immaturity of the big data science discipline and the still evolving enabling technologies, being a fast follower might not be such a bad thing when it comes to big data deployment. After all, “the best way to walk through a minefield is to follow the footsteps of someone who has crossed it successfully,” and big data can be quite a minefield.
Even digital behemoth Google has had its share of big data blunders. Remember the Google Flu Trends (GFT) data aggregation tool? Google tried to use search result data to project real-time trends in the circulation of the flu in different countries and regions around the world. Their results were wildly overstated as a result of a number of false assumptions made by the company. The project is often cited as an example big data’s Achilles heel—if you are gathering the wrong information or asking the wrong questions, your results are destined to be flawed.
So, as supply chain organizations prepare to move their data analytics’ strategies from discussion to execution, they must approach the undertaking with a clear vision of what they hope to achieve, as well as an honest assessment of their readiness to make the investments and cultural changes necessary to capture the full potential of the opportunity.
Here’s a preview of some of insights and best practices in this section, shared by supply chain thought leaders from their experiences with supply chain data—big, small and everything in between.
- Lenovo Vice President of Strategy and Innovation Mick Jones, Lenovo’s Prescription for Supply Chain Success: “In many cases, it was about using tools that we already had in place in a different ways…dashboards, Excel-based sourcing analysis. We just needed to take the next step and forget all the hype and focus on what we could do.”
- Avnet CIO Steve Phillips, 5 Lessons Learned from Avnet’s Big Data Implementation…So Far: “The old expression ‘garbage in, garbage out’ absolutely applies here. The larger and more complex your data environment is, the more you need a strong Master Data Governance policy.”
- Flextronics Chief Procurement Officer Tom Linton, We Reap What We Sow: “No matter how much technology you throw at the supply chain, if you keep operating with business/process rules that were established years, or even decades, ago, you are not going to be able to affect the kind of supply chain improvements possible through today’s data analytics programs.”
- Edith Simchi-Levi, Vice President of Operations for OPS Rules, Supply Chain Analytics Centers of Excellence: “As companies think about what they need to do to build out their supply chain data analytics capabilities, one option they should consider is the creation of a Center of Excellence (COE) focused on supply chain analytics.”